This document explains the architecture of the Media Manager Service and Transcoder Service which are components of the Universal-Inbox within ICEBERG. The Media Manager service allows access to mail related mime types by heterogeneous devices accross any mail protocol through the transcoding of data. The Transcoder Service is used to perform data transformations of audio and text.
Detailed instructions for installing the Transcoder Service are here .
Detailed instructions for installing the Media Manager Service are here .
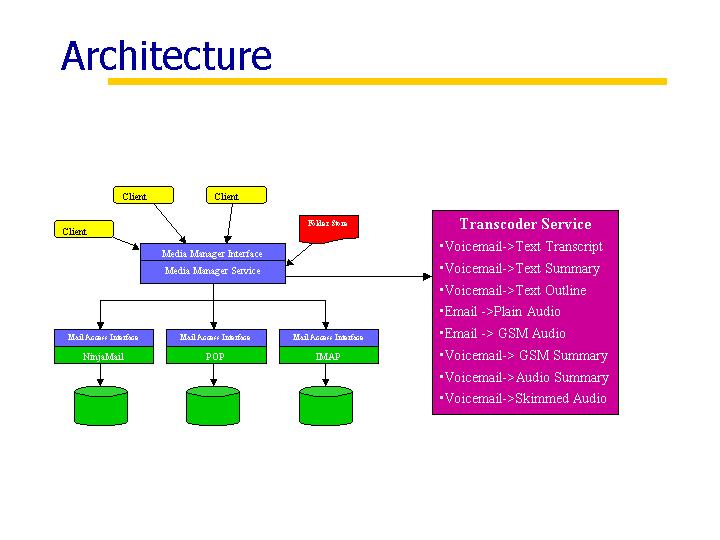
The Media Manager service is implemented as a Ninja iSpace service. Its purpose is to handle mail related mime types along with our own mime attribute extensions, across any mail protocol. The Media Manager implements the Media Manager interface. It receives requests from clients and in turn accesses the Mail Access interface. It optionally uses the Transcoder service to perform transformations on content objects. Users access their mail with calls to the Media Manager. These calls will access all mail across all the mail protocols a user wishes to use. The components of the Media Manager are the Media Manager interface, the Mail Access interface, the mail protocol table, the folder store, media messages, and content objects.
The Media Manager interface exports four methods: getFolders, getList, getMessage, and getMessageContent. getFolders returns the names of all folders for a given user across mail protocols. getList retrieves a specified number of messages from a given folder. getMessage retrieves a specified message, and getMessageContent retrieves a specified message part as a specified mime type.
The above methods access the Mail Access interface and call getMAFolders, getMAList, getMAMessage, and getMAMessageContent respectively. This interface may be implemented for any mail protocol- i.e. NinjaMail, POP, and IMAP. Currently only NinjaMail Access is implemented. For demonstrating the Media Manager with Ninja Mail Access we have populated a Ninja MailStore with a test set of email and voice mail.
The mail protocol table stores an instance of all the mail protocols that are currently implemented on behalf of the Media Manager and is loaded when the Media Manager starts. When a client makes a request the mail protocol table is consulted to get an instance of the desired mail protocol. Then the query is made on that instance. In some cases the folder store may be consulted. The folder store contains records of every protocol where a user has mail folders. For example, a user may want to get a list of all their mail folders. The folder store is the only persistent data in the Media Manager. This data could be stored in a distrib uted hash table on a Distributed Data Structure platform. Currently, it must be maintained by an administrator.
Media messages are simplified versions of regular mail messages and are meant to be used with simpler clients. Only a few headers are handled and only one level of mime parts is supported. In other words, attachments within attachments are not handled. Each media message has a unique identifier called a mediaref which contains the name of the protocol and the unique identifier within that protocol. Each part of a media message is identified by its contentid. In order to avoid transferring unnecessary data, contentids and mediarefs are passed unless content is specifically requested.
The parts of a message are referred to as content objects and are specified by their contentids. Each content object has a mime type. The Media manager supports text, audio, and multipart mime types. In addition we have our own mime attribute extensions; skimmed audio, text summary, transcript, outline, and audio summary. By passing a contentid and the desired mime type to the getMessageContent() method, a client may have a content object returned as a particular mime type. The Transcoder service does the actual transcoding. This is useful for clients who do not have speakers, for example, and need their audio content displayed as text.
The Transcoder Service is a Ninja iSpace service which transforms data. It is responsible for transforming data into plain text, transcript, text summary, text outline, plain audio, audio summary, gsm audio, gsm summary, and skimmed audio. Transcript represents content that has been generated by doing speech recognition. Text summary represents automatic text summarization done by extracting the emphasized words found using pitch detection and key words found using natural language processing, NLP. Outline organizes a text summary into an outlined form, which is generated by using the talk spurts of the audio file. Plain audio may represent original audio or that which has been synthesized from a text email. Audio summary is audio generated from the text summary. Skimmed audio is audio that has had all pauses removed.
The basic transformations from speech to text and text to speech use programs developed with IBM's speech recognizer and synthesizer software development kit, ViaVoice. We used the Speech Recognition Control Language (SRCL) to define a grammar which recognizes names and phone numbers for the text summaries. The SRCL also has an annotation feature which allows key words and phrases to be tagged when the grammar is defined. Both the annotation and recognized phrase are returned to the application. This simplifies the task of parsing of the results for meaningful information. In order to set our input and output sources to and from the speech engine, we also created a custom audio library.